大数据 大数据由巨型数据集 组成,这些数据集大小常超出人类在可接受时间下的收集 、庋用 、管理和处理能力[16] 。大数据的大小经常改变,截至2012年,单一数据集的大小从数太字节 (TB)至数十兆亿字节 (PB)不等。
分布式 分布式存储是一种数据存储技术,通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。
分布式计算是一种计算方法,和集中式计算是相对的。
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。
分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
why 随着数据量的增大,单从扩大计算机的资源方面已经很难满足日常需求并且费用昂贵。从而引起分布式的出现,分布式的出现可以将数据存储在多台计算机上,使用多台计算机来进行运算,解决了单个计算机资源不足的痛点
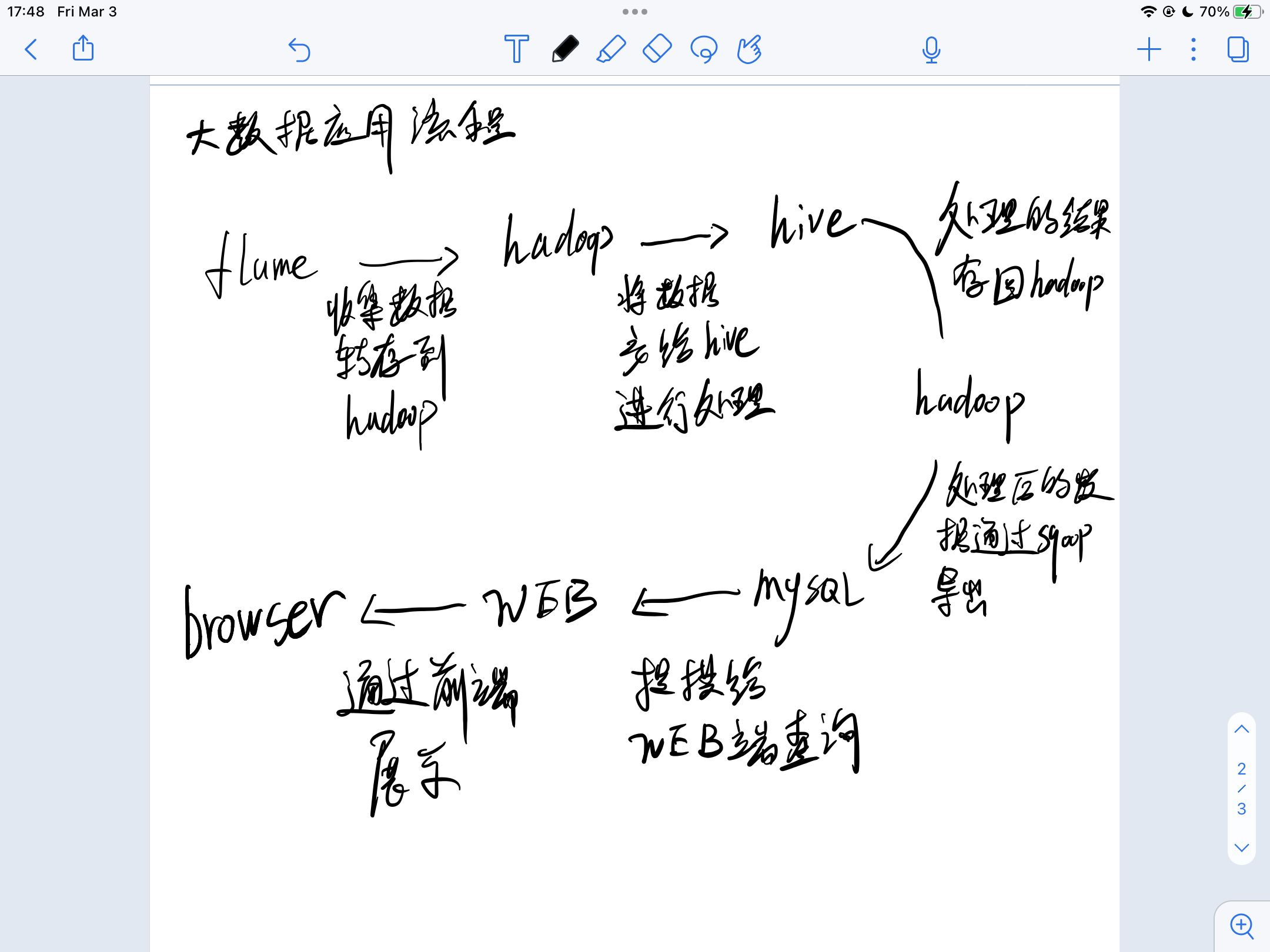
本文 本文通过是通过对网站日志数据的处理这一例子来学习大数据的大概流程
贴一个大致流程图(毕竟是给自己看的,凑合
flume -> hadoop -> hive -> hadoop -> mysql -> webserver -> browser
关于 定时任务这块 做个了解 并没有源源不断的数据
本文记录每个工具的基本使用
环境 CentOS 7 1核2G 测试环境仅使用一台机子
jdk 1 2 3 4 5 vim /etc/profile export JAVA_HOME=/opt/server/jdk1.8.0_361export PATH=${JAVA_HOME} /bin:$PATH source /etc/profile
hadoop Hadoop 组件之间需要基于 SSH 进行通讯,配置免密登录后不需要每次都输入密码
1 2 3 4 5 6 7 8 9 vim /etc/hosts 192.168.80.100 server ssh-keygen -t rsa cd ~/.sshcat id_rsa.pub >> authorized_keys chmod 600 authorized_keys
配置hadoop
1 2 vim hadoop-env.sh export JAVA_HOME=/opt/server/jdk1.8.0_361
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <configuration> <property> <!--指定 namenode 的 hdfs 协议文件系统的通信地址--> <name>fs.defaultFS</name> <value>hdfs://server:8020</value> </property> <property> <!--指定 hadoop 数据文件存储目录--> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data</value> </property> </configuration> <configuration> <property> <!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1--> <name>dfs.replication</name> <value>1</value> </property> </configuration> vim workers server
初始化并且启动hdfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 关闭防火墙,不然web访问不到 sudo systemctl stop firewalld sudo systemctl disable firewalld cd /opt/server/hadoop-3.1.0/bin./hdfs namenode -format cd /opt/server/hadoop-3.1.0/sbin/HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root cd /opt/server/hadoop-3.1.0/sbin/./start-dfs.sh jps
web ui 界面端口为:9870
hadoop(yarn) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME} </value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME} </value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME} </value> </property> </configuratio <configuration> <property> <!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在Yarn 上运行 MapRedvimuce 程序。--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root ./start-yarn.sh hadoop jar /opt/server/hadoop-3.1.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar pi 2 10
web ui 端口 8088
mysql 1 2 3 4 5 6 7 8 9 10 11 mysql -u root -p Enter password: set global validate_password_policy=0 ;set global validate_password_length=1 ;set password =password ('root' );grant all privileges on *.* to 'root' @'%' identified by 'root' ;flush privileges ;
hive 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cd /opt/server/apache-hive-3.1.2-bin/libcd /opt/server/apache-hive-3.1.2-bin/confcp hive-env.sh.template hive-env.sh vim hive-env.sh HADOOP_HOME=/opt/server/hadoop-3.1.0 vim hive-site.xml <?xml version="1.0" ?> <?xml-stylesheet type ="text/xsl" href="configuration.xsl" ?> <configuration> <!-- 存储元数据mysql相关配置 /etc/hosts --> <property> <name>javax.jdo.option.ConnectionURL</name> <value> jdbc:mysql://server:3306/hive? createDatabaseIfNotExist=true &useSSL=false &useUnicode=true &chara cterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> </configuration> cd /opt/server/apache-hive-3.1.2-bin/bin./schematool -dbType mysql -initSchema
使用起来和sql类似
flume 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 vim taildir-hdfs.conf a3.sources = r3 a3.sinks = k3 a3.channels = c3 a3.sources.r3.type = TAILDIR a3.sources.r3.filegroups = f1 a3.sources.r3.filegroups.f1 = /var/log /nginx/access.log a3.sources.r3.positionFile = /opt/server/apache-flume-1.9.0-bin/tail_dir.json a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://server:8020/user/tailDir a3.sinks.k3.hdfs.fileType = DataStream a3.sinks.k3.hdfs.rollSize = 134217700 a3.sinks.k3.hdfs.rollCount = 0 a3.sinks.k3.hdfs.rollInterval = 10 a3.sinks.k3.hdfs.minBlockReplicas = 1 a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
启动 flume
1 bin/flume-ng agent -c ./conf -f ./conf/taildir-hdfs.conf -n a3 -Dflume.root.logger=INFO,console
sqoop 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/confcp sqoop-env-template.sh sqoop-env.sh vim sqoop-env.sh export HADOOP_COMMON_HOME=/opt/server/hadoop-3.1.0export HADOOP_MAPRED_HOME=/opt/server/hadoop-3.1.0export HIVE_HOME=/opt/server/apache-hive-3.1.2-bincd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/libcreate table test1( id int unsigned auto_increment, name varchar(20), primary key(id) ); insert into test1(name) values("fuck" ); ./sqoop import \ --connect jdbc:mysql://192.168.80.100:3306/sqoop \ --username root --password root \ --table test1 \ --target-dir /appendresult \ --incremental append \ --check-column id \ --last-value 1 create database exportfortest; create table test1( id int unsigned auto_increment, name varchar(20), primary key(id) ); ./sqoop export \ --connect jdbc:mysql://192.168.80.100:3306/ctfd \ --username root \ --password root \ --table test1 \ --export-dir /appendresult/part-m-00000 ./sqoop job --create job_test2 \ -- import \ --connect jdbc:mysql://192.168.80.100:3306/sqoop \ --username root \ --password-file /mysql/pwd /mysqlpwd.pwd \ --table test \ --target-dir /crontabtest \ --check-column last_mod \ --incremental lastmodified \ --last-value "2023-03-02 09:20:08" \ --m 1 \ --append
数据处理流程 寒假有办了个线上冬令营,把网站的日志拿过来做分析
数据来源:ctfd 的 logins.log 日志文件
导入数据
1 2 3 4 5 [root@bigdatalearning data] [root@bigdatalearning data] [root@bigdatalearning data] Found 1 items -rw-r--r-- 1 root supergroup 83483 2023-03-03 18:24 /ctfd/logins.log
hive数据处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use ctfd; create table logins (content string); load data inpath '/ctfd/logins.log' into table logins; CREATE TABLE logins_res (visit_id string,visit_count int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; INSERT INTO TABLE logins_res SELECT visit_id, COUNT(*) AS visit_count FROM ( SELECT regexp_extract(content, '\\[(.*?)\\]', 1) AS visit_time, regexp_extract(content, '\\d+\\.\\d+\\.\\d+\\.\\d+', 0) AS ip_address, regexp_extract(content, ' - (\\w+) ', 1) AS visit_id FROM logins ) log_parsed GROUP BY visit_id;
sqoop 转存
1 2 3 4 5 6 7 8 9 10 11 12 13 create table test1( name varchar(50), value int ); ./sqoop export \ --connect jdbc:mysql://192.168.80.100:3306/ctfd \ --username root \ --password root \ --table test1 \ --export-dir /user/hive/warehouse/ctfd.db/logins_res
web
用python写个后端返回数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from flask import Flask,jsonifyimport pymysql as pmqfrom pymysql import cursorsapp = Flask(__name__) @app.route("/api" def index (): con = pmq.connect(host="localhost" , user="root" , password="root" , database="ctfd" , cursorclass=cursors.DictCursor) cur = con.cursor() cur.execute('select * from test1' ) results = cur.fetchall() return jsonify(results) if __name__ == "__main__" : app.run(host="0.0.0.0" ,port = "15000" ,debug=True )
browser
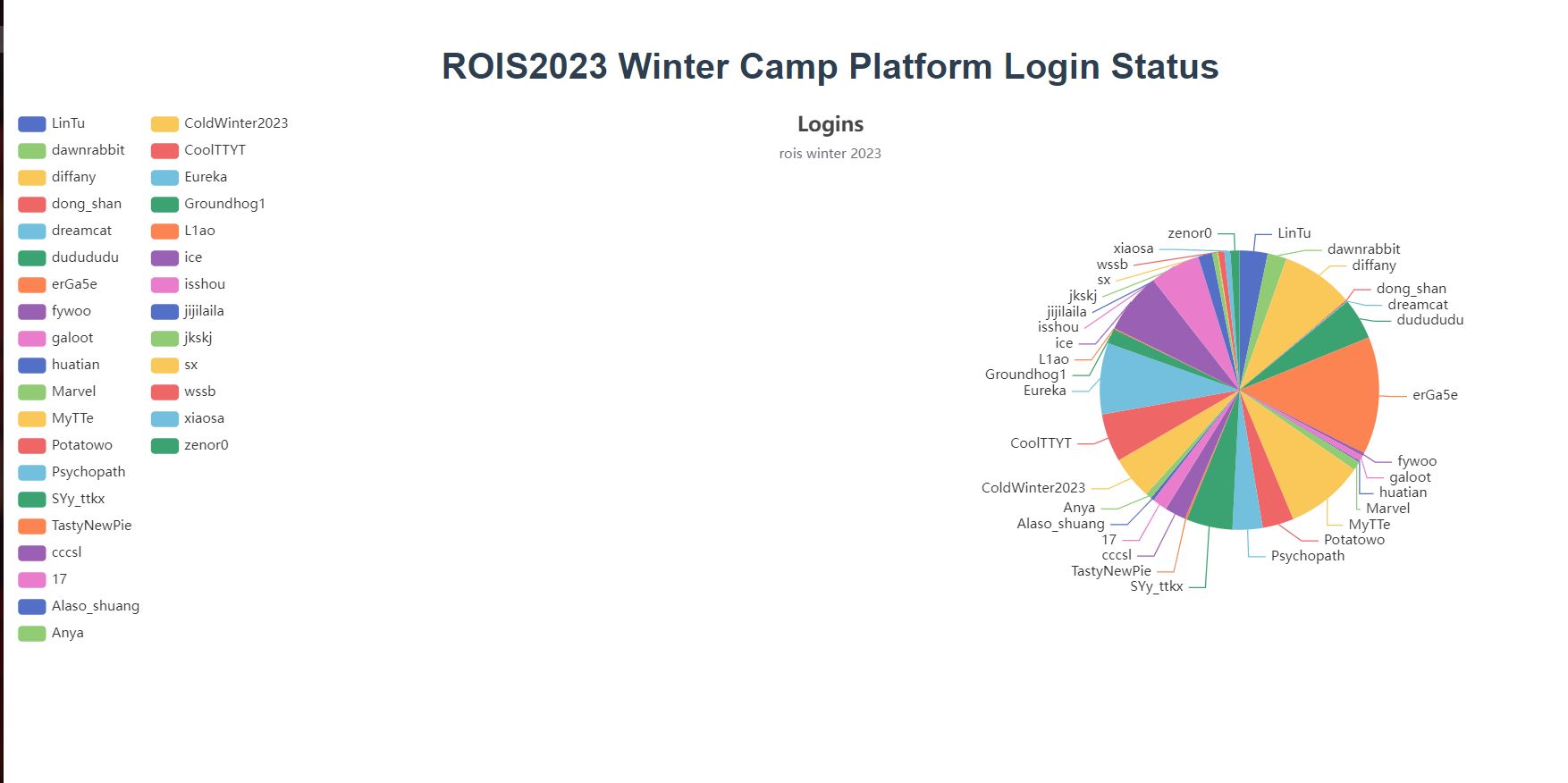
前端用vue + echarts 展示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 <template> <h1>{{ msg }}</h1> <div class="hello" id="main"> </div> </template> <script> import * as echarts from 'echarts'; import 'echarts/map/js/china.js' import axios from 'axios'; export default { data: function () { return { option: { title: { text: 'Logins', subtext: 'rois winter 2023', left: 'center' }, tooltip: { trigger: 'item' }, legend: { orient: 'vertical', left: 'left' }, series: [ { name: 'Access From', type: 'pie', center: ['75%', '50%'], radius: '50%', data: [], emphasis: { itemStyle: { shadowBlur: 10, shadowOffsetX: 0, shadowColor: 'rgba(0, 0, 0, 0.5)' } } } ] } } }, name: 'HelloWorld', props: { msg: String }, mounted() { var myChart = echarts.init(document.getElementById('main')); axios.get("/api").then((response) => { this.option.series[0].data = response.data; // 绘制图表 this.option = { ...this.option }; myChart.setOption(this.option); }); // var mydata = [ // { value: 1048, name: 'Search Engine' }, // { value: 735, name: 'Direct' }, // { value: 580, name: 'Email' }, // { value: 484, name: 'Union Ads' }, // { value: 300, name: 'Video Ads' } // // ]; // this.option.series[0].data = mydata; // // 绘制图表 // this.option = { ...this.option }; // myChart.setOption(this.option); } } </script> <!-- Add "scoped" attribute to limit CSS to this component only --> <style scoped> .hello { width: 100%; height: 500px; } </style>
最终效果
问题与思考 todo